研究紹介
ディープラーニング
深層学習と自動運転
自動運転システムと深層学習(Deep Learning)は密接に関連しています。深層学習は、自動運転車が周囲の環境を認識し、適切な判断を下すための重要な技術です。特に、画像および点群認識技術を使用して道路標識や歩行者、車両を検出し、リアルタイムで周囲の状況を把握します。また、深層学習は予測モデルの作成にも使用され、他の車両や自転車、歩行者等の動きを予測することで、安全で効率的な運転を可能にします。自動運転システムは、これらの技術を組み合わせて、より高度な運転機能を実現しています。安積研究室では組込みデバイスの限られたリソース下における効率的な深層学習方法の提案や実装する研究を行っています。
学習について
従来の機械学習
深層学習におけるモデルの学習には、大量の学習データと高い計算能力が必要です。一般的には、豊富な計算リソースを持つコンピュータに全ての学習データを集約し、そこでモデルの学習を行います。学習データをモデルに入力し、予測結果と正解の誤差を計算します。そして、この誤差を最小化するために計算された情報(勾配情報)を基にモデルのパラメータを調整します。
この学習方法により、全てのデータを用いて学習できるため、モデルの性能を最大化できます。一方で、学習データのプライバシ保護や、識別情報の付与(ラベリング)に関する課題があります。
Federated Learning
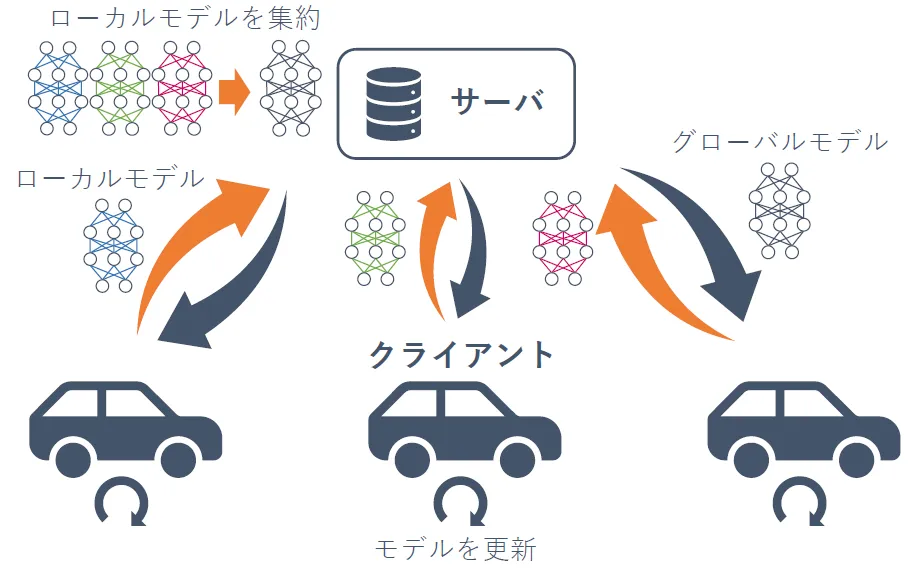
Federated Learning(FL)は、分散したデバイス(自動運転車やスマートフォンなど)上でモデルを学習する技術であり、データを各々のデバイスに保持したままプライバシを保護しつつ、モデルを更新します。各デバイスがローカルデータでモデルを学習し、その結果を中央サーバに送信します。サーバは集約されたモデル更新を行い、改善されたモデルを各デバイスに送信します。自動運転システムでは、FLを利用してデバイス間で学習を共有できます。これにより、異なる環境での運転データを統合し、より汎用的で適応性の高いモデルが構築されます。プライバシ保護を維持しつつ、多様なデータセットから学ぶことで、安全性と精度の向上が期待できます。
しかし、この手法ではそれぞれのデバイスで機械学習を行うため、計算能力が必要になりますが、一般的にデバイスにはスーパーコンピュータほどの計算能力はありません。本研究室ではこの課題を解決するために、メニーコアプロセッサといったデバイスを用いて、処理を最適化し、解決を目指します。
Split Learning
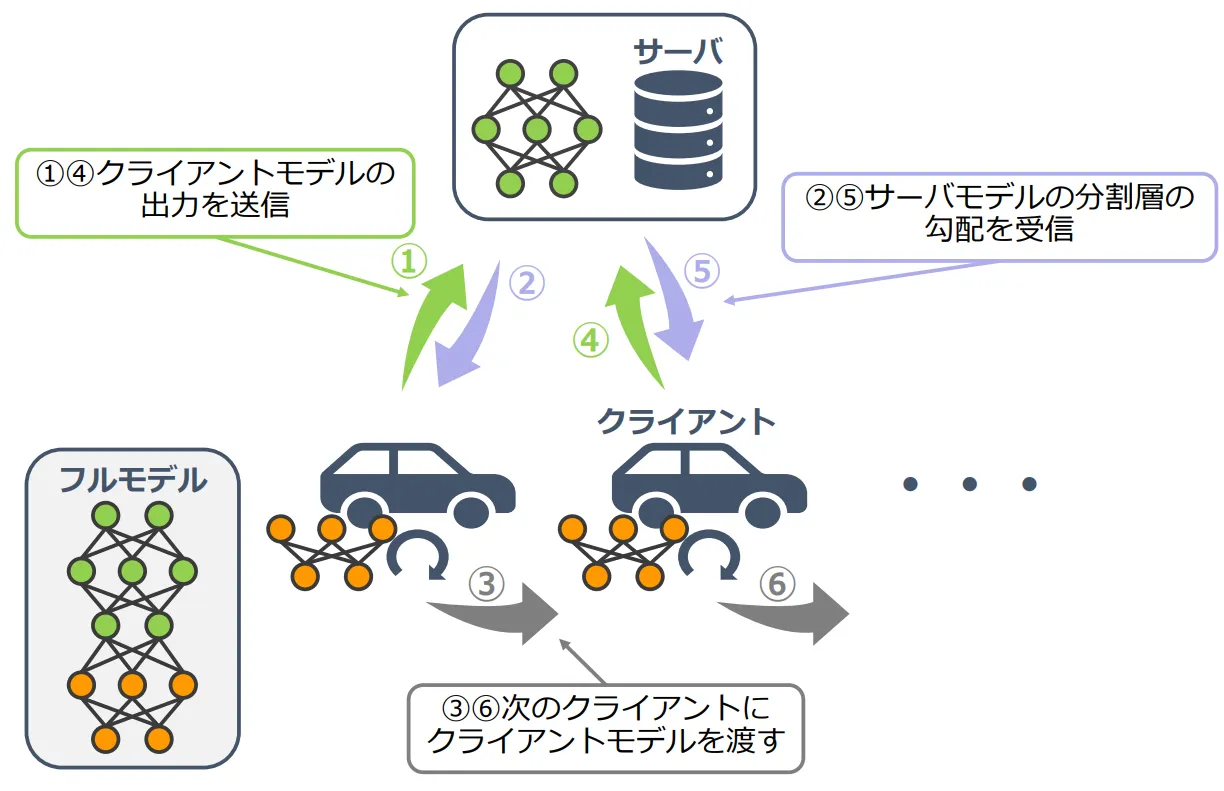
Split Learning(SL)は、Federated Learning(FL)と同様に、各クライアント(データ保持者)のローカルデータのプライバシを保護しつつ、複数のクライアントが協調的に学習を行うアプローチです。SLでは学習するモデルを分割して、クライアントは入力層側(クライアントモデル)を保持し、中央サーバは出力層側(サーバモデル)を保持します。そして、クライアントはローカルデータをクライアントモデルに入力し、その出力を中央サーバに送信します。中央サーバは、クライアントから受信したデータをサーバモデルに入力し、損失を計算して、サーバモデルを更新します。さらに、中央サーバはクライアントから受信したデータに対する勾配情報も計算し、クライアントに送信します。クライアントは中央サーバから受信した勾配情報を基に、クライアントモデルを更新します。このやりとりを繰り返したのち、学習中のクライアントは次に中央サーバと通信するクライアントに自身のクライアントモデルを渡します。以上の流れを複数のクライアントでリレー形式で進めていくことで、SLの学習が進みます。SLの利点は、FLと比べてクライアントの計算量が少なく、FLが実行できないデバイスでも、ローカルデータのプライバシを保護しつつ、協調的に学習が行える点です。しかし、中央サーバとの通信回数や、リレー形式の学習による並列性の欠如といった課題があります。
自動運転における自動ラベリング
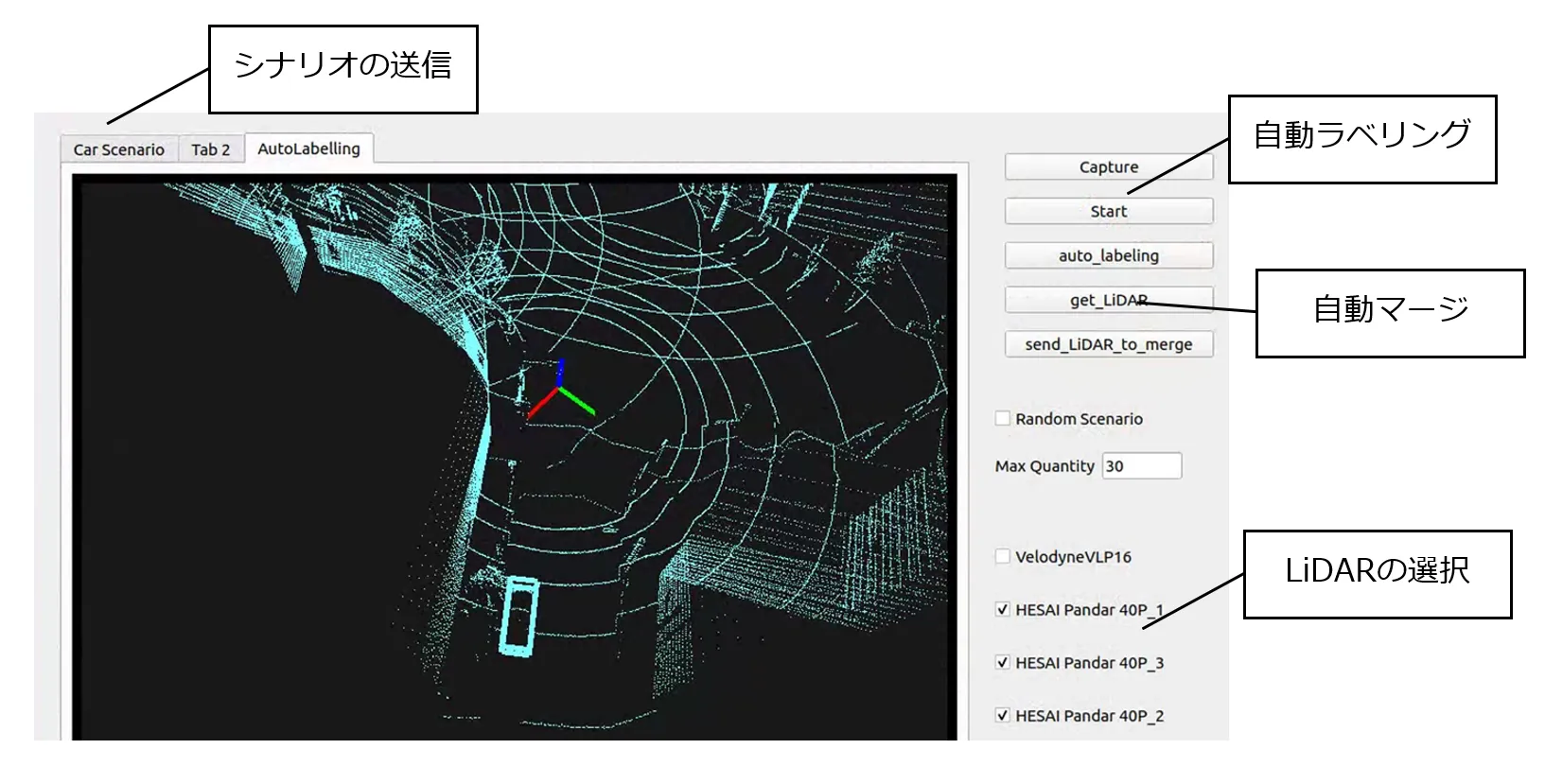
ラベルは車や背景といったオブジェクトにつけられる識別情報で、オブジェクトに付与するプロセスをラベリングと言います。点群自動ラベリングには、シミュレータに基づく方法と現実世界に基づく方法があります。シミュレータに基づくラベリングは、シミュレータを使用して仮想環境内で高精度な三次元データを生成し、それに自動でラベルを付ける手法です。この方法の利点は、シナリオを自由に設定でき、データ生成速度の速さ、低コストであることです。しかし、シミュレータのデータは現実のデータと異なる可能性があり、完全なリアリティを再現することは難しいです。一方、現実世界に基づくラベリングは、LiDARやカメラなどのセンサを使用して実際に点群データを収集し、その後手動または自動化ツールでラベルを付ける方法です。これはデータの信頼性が高く、アノテーションの品質も非常に高いですが、データ収集やアノテーションにかかる労力や時間といったコストが非常に大きいという欠点があります。
現実世界のノイズをシミュレータに追加することでより、現実世界に近いデータを生成することができるようになります。ノイズを追加したデータを用いて学習したモデルは、現実世界の複雑なデータを識別できるようになります。この手法は、現実世界でのデータラベリング作業を大幅に削減するだけでなく、コストの削減にも大きく貢献します。
※アノテーション・・・ラベル付けデータをファイルとして出力すること
推論について
推論とは
深層学習では、学習済みモデルを用いて推論を行います。推論とは、目的となるタスクにおいて、データに対する予測を行うことです。学習済みモデルで画像や点群といったデータを処理することで、入力データに対する予測結果を得ることができます。一般に、モデルの層が増えると精度は高くなりますが、推論にかかる時間は増加します。リアルタイム性が求められるシステムにおいては、精度と時間のトレードオフを考慮する必要があります。
Split Computing
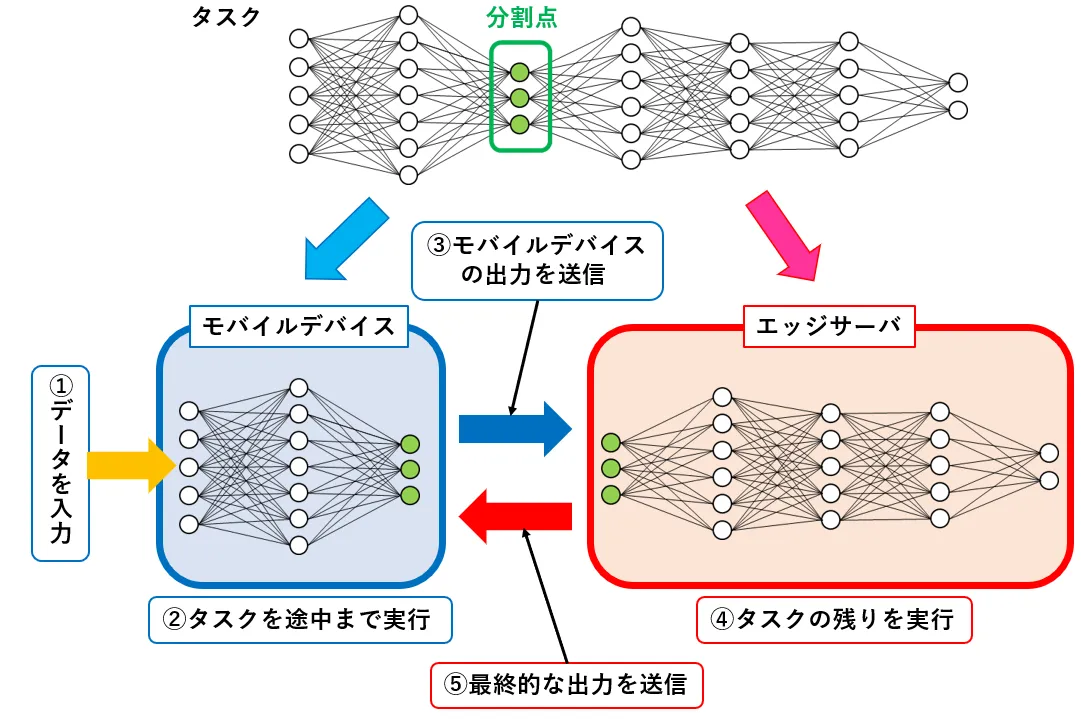
Split Computing(SC)は、タスクをモバイルデバイスとエッジサーバで分割して実行することで、モバイルデバイスへの計算負荷を抑えながら、精度を維持できる手法です。近年、モバイルデバイス上で物体検出などのタスクを実行する需要が増加していますが、モバイルデバイスは計算能力やエネルギー消費量に制限があるため、複雑なタスクの実行に時間がかかったり、エネルギー消費の制約を満たせず実行が難しいという問題があります。このため、モバイルデバイス上ではタスクの複雑度を低減させる必要があり、これは精度の低下をもたらします。タスクを計算能力の高いエッジサーバで実行することで、タスクの複雑度を下げることなく精度を維持できますが、モバイルデバイスが得た膨大なデータをエッジサーバに送信する必要があるため、データの送信による大きな遅延が発生します。SCでは、タスクの途中でデータサイズが小さくなる場所までモバイルデバイスで実行し、タスク途中のデータをエッジサーバに送信してタスクの残りを実行することで、データの送信による遅延を最小限に抑えながら、精度を維持できます。